从 Cursor 到 Coding CLI:我如何用 TUI-based Coding Agent 重构开发工作流
本文整理自 2026 年 3 月 6 日的公司内部技术分享。使用了 AI 帮助整理 transcripts。
这次分享围绕三个问题展开。
第一,讲为什么我现在更愿意从 Cursor 这类编辑器型工具,转到终端里的 coding agent。 第二,以 Claude Code 为例,介绍 coding agent 的工作方式。 第三,讲我自己日常开发的 workflow。
语言的边界,也是 AI 编程的边界
我最开始想引用维特根斯坦的一句话:
Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt.
直译过来就是:
我的语言的边界,意味着我的世界的边界。
把这句话放到 AI 编程里,我的理解便是:如果你讲不清自己想做什么,AI 大概率也做不好。能不能把需求说明白,直接决定了它能做到什么程度。和 AI 编程工具协作,最基础的要求是把想法拆开、说清楚。你要知道自己想要什么,也要能把目标拆成 agent 能理解、能执行、能验证的形式。
很多人会把 prompt 写不好归因于语文不好。我觉得更常见的问题在思路上,而不在表达或者词汇上。一个人可以认识很多英文单词,但如果没把问题拆开,没说清目标、约束和验收标准,prompt 仍然会很差。这个能力可以练。我自己的办法很笨:长期强迫自己和 AI 用纯英文做有逻辑的对话,反复练怎么描述目标、拆任务、加限制、要求验证。练久了,差别很明显。
AI Coding 的三个阶段
为了方便讨论,我先粗分一下 AI coding 的几个阶段。这个分类来自 Cursor 创始人的一个观察:模型变强之后,写代码的方式也跟着变。
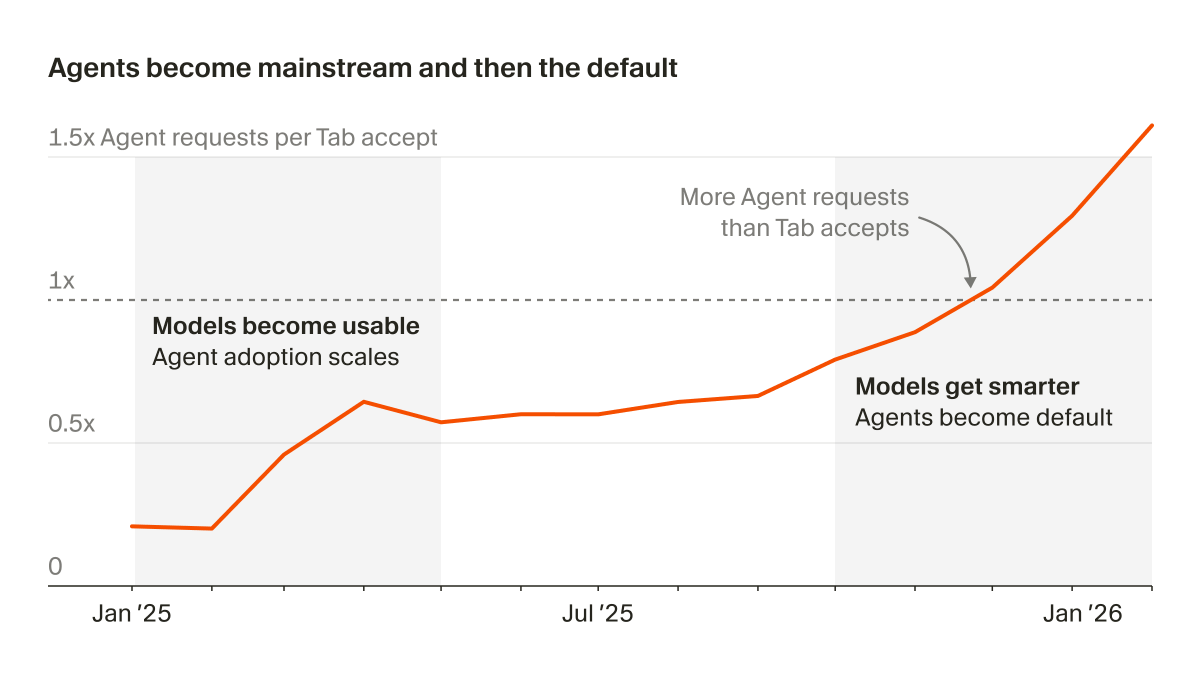
第一阶段是行内补全时代。Cursor Tab 是这里的典型代表。这个阶段里,人还是主要的 coder,AI 做的是局部补全。它很像一个更聪明的 autocomplete。
第二阶段是 local agent 时代,也就是我们现在主要处在的阶段。你不再只是让 AI 写一段代码,而是给它一个任务,让它理解项目、规划步骤、编辑文件、运行测试、bugfix。从 Cursor 自己的数据也能看到这个变化:以前 Tab 用户比 agent 用户多,现在反过来了,agent 用量超过了 Tab。
第三阶段是 cloud agent 时代。你在云端描述需求,让 coding agent 在远程环境里独立跑完整个任务。
我对第三阶段目前持保留态度。我不是反对这个方向,只是怀疑现在的模型能不能稳定做完长任务。真实工作里,一个需求经常横跨多个项目、多个服务和一堆历史约定。本地 agent 可以读取文件系统里的不同项目、我的 CLAUDE.md、我的工作区和我临时给的上下文。云端 agent 能不能同样理解这些关系,长任务中会不会丢细节,我现在还不太放心。
也可能是我的语言表达能力还不够强,没办法一次性把所有细节交代给 AI。但绕一圈还是回到前面那件事:你能不能把问题讲明白。
为什么我从编辑器转向终端
接下来讲我为什么会从 Cursor 这样的编辑器型工具,转向终端型 coding agent。我一开始也担心过:如果不盯着编辑器看代码,只在终端里和 agent 对话,会不会效果更差?后面实际用下来,这个担心基本没有成立。
行内补全这件事正在变得不那么重要。模型变强之后,我们很多时候不再围绕“补一行代码”设计工作流,而是让 agent 理解任务、调用工具、改多个文件、跑测试、看结果。
这也是为什么我觉得终端型 coding agent 更接近 AI native。有些产品只是加了一个聊天入口,有些产品的整个交互就是围着模型能力设计的,后者才是真正的 AI native。
Cursor 断网之后,它仍然是一个编辑器,只是 AI 功能不能用了。但 Claude Code 这类工具如果没有模型、没有 API,它基本就不能工作。它不是在传统工具上加了一层 AI,它本身就是围绕模型能力设计出来的。如果主要目标是让 agent 调工具、切会话、压上下文,终端通常更顺手;如果主要是人盯着代码改,编辑器还是更直接。
还有一个细节很能说明问题。Cloudflare 现在已经开始把 agent 当成一等公民处理,它们可以返回更适合模型读取的 Markdown,而不是让模型直接面对 HTML DOM。以后软件接口可能不只为人类设计 UX,也会给 agent 留一个更容易处理的入口。
还有一个很现实的问题:多任务开发。在日常工作里,一个项目可能同时有几个需求。你可能要开多个 Cursor 窗口,在不同项目、不同分支、不同上下文之间切换。编辑器重,窗口多了也卡,人的注意力也容易被 UI 切换分散。终端轻很多。CLI/TUI 对 agent 也更友好。
并行开发的基础设施:tmux 和 Git worktree
开始用终端做 AI 编程之后,很快就会遇到一个问题:怎么管理一堆 session?如果只是开很多终端 Tab,十几个项目一多起来,基本没什么可读性。更麻烦的是,终端进程一关,之前开的东西可能就全没了。
我用的是 tmux。它是一个很老但很好用的 terminal multiplexer。你可以用 session、window、pane 三个层级组织终端。一个 session 对应一个大工作区;一个 window 负责一个任务;一个 pane 里放 Claude Code,旁边再放 Codex、测试命令或日志。终端模拟器退出以后,tmux session 还挂在后台。
我实际会这样用:比如让 Claude Code 和 Codex 交叉找 bug。一个 agent 找完问题后,我再把结果扔给另一个 Claude Code session,让它和我一起验证、修复。这样不同任务之间不会挤在一个上下文里,也不会互相污染。
另一个工具是 Git worktree。它允许你在同一个仓库里同时维护多个工作目录,每个目录对应不同分支。这样你可以在一个项目里同时跑多个需求,每个需求一个 worktree,每个 worktree 里再开独立的 Claude Code。Claude Code 后来原生兼容了 tmux 和 Git worktree,Cursor 也在补类似能力。
理论上,只要脑子跟得上,你可以同时编排很多条工作流。这是 TUI 很方便的地方。
Claude Code 这类 Agent 是怎么工作的
我之所以拿 Claude Code 做例子,是因为它在终端型 coding agent 里确实做得最好。上下文理解能力强,skills 生态也丰富。当然,这里有我的使用偏好,我只是讲我自己用下来的感受。
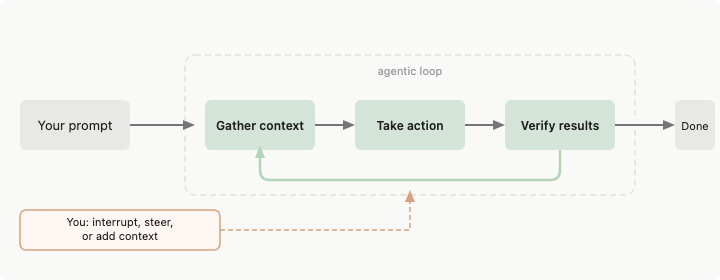
它大概会反复做几件事:
- Gather Context:读取文件、搜索代码、查看错误、运行命令,构建对当前问题的理解。
- Take Action:根据上下文执行动作,比如编辑文件、运行脚本、调用工具。
- Verify Results:检查动作是否成功,比如重新运行测试、查看编译错误、确认输出是否符合预期。
这个循环会一直重复,直到模型认为任务完成。
这里有个点很容易被忽略:它什么时候停下来,不是由某个硬编码算法决定的。它会看自己这一轮操作有没有让最初的目标更接近完成。你一开始说得越含糊,它后面就越容易靠猜。
如果你说“修一下这个 bug”,它会根据自己对 bug 的理解去判断是否修好了。如果你说“确保 user_test.go 里的测试全部通过”,它就有了更明确的停止条件。
所以 prompt 不能只写一个模糊愿望。最好有目标,有限制,也有验收标准。否则 agent 会自己猜,猜得对不对就很看运气。
Session、Context 和 Subagent
Claude Code 里有几个绕不开的概念:session、context、subagent。
每次你在某个目录下启动 Claude Code,它都会有一个 session。这个 session 有自己的上下文。上下文里可能有当前对话、CLAUDE.md、MCP server 信息、skills 的描述性元信息,也包括它在任务里逐步读取到的内容。上下文快满时,它会做 auto compact,把前面的内容压缩后带到新的上下文里。
上下文是有限的,不是什么东西都该塞进去。CLAUDE.md 写太长,MCP server 接太多,skills 全部打开,都会把噪声带进来。无关信息太多,模型注意力会被冲散。
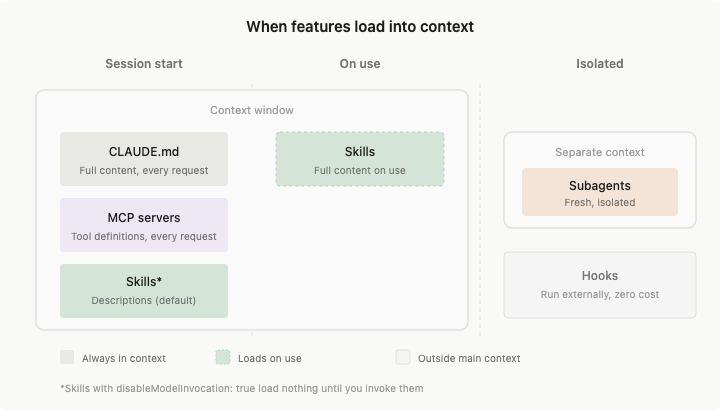
这就是为什么我很推荐 subagent。并行只是次要原因,它真正的好处是隔离上下文。
比如 code review。假设我维护了一组 coding patterns,我想检查这次代码变更是否符合每一个 pattern。这个时候我可以让主 session 为每个 pattern spawn 一个 subagent。每个 subagent 只负责一个检查方向,最后把结果返回主 session。
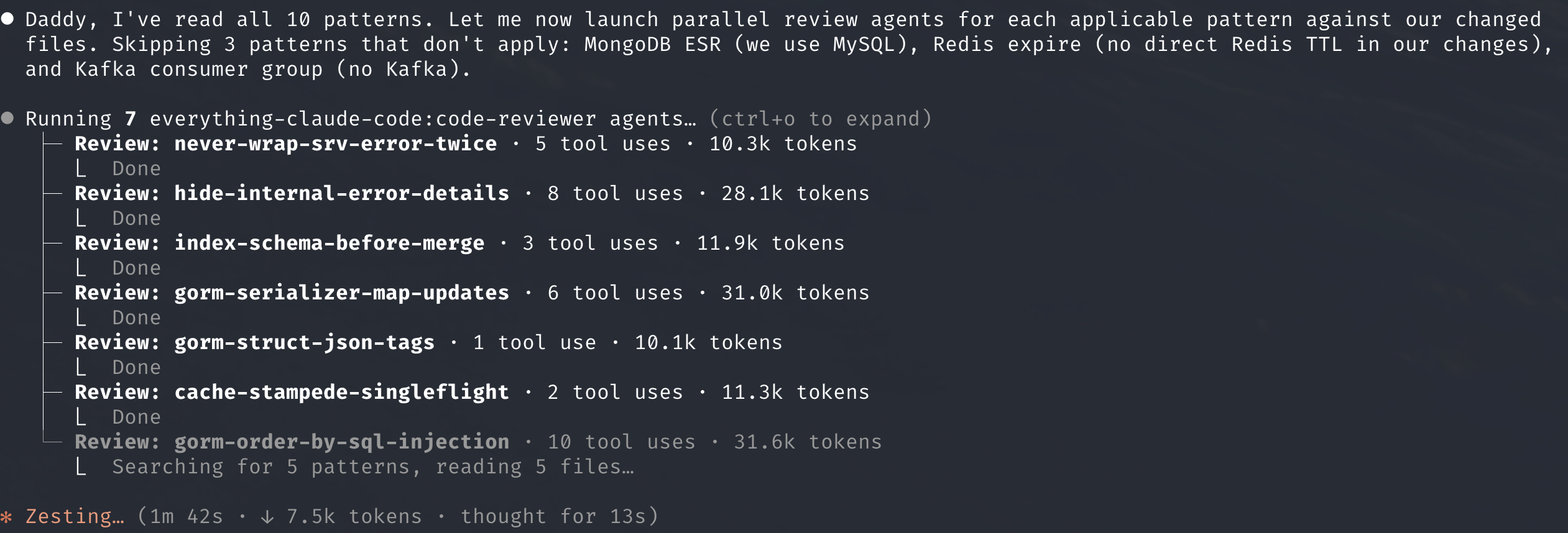
这样做的好处是,每个 subagent 的调查过程不会污染主 session。主 session 只需要关心两件事:一开始派出去的任务,以及最后收回来的结果。
所以我的经验是:能用 subagent 的场景,就尽量用 subagent。不是所有任务都适合并行,有些测试和修改必须串行。但能拆开的活,我通常会分给 subagent,这样主 session 不会被调查过程塞满。
Agent Teams 和 subagent 不太一样。subagent 更像上下级关系:主 session 分配任务,subagent 返回结果。Agent Teams 更像平级 agent 之间互相交流。这个能力听起来很强,但我自己还没有深度使用,这里就不展开。
Memory:把经验沉淀进 Agent 的长期上下文
Claude Code 另一个让我觉得有意思的地方,是它的 memory 机制。
我主要把它分成几类:CLAUDE.md、Auto Memory,以及类似 Rules 的作用域记忆。
CLAUDE.md 可以分成全局和项目级。全局 CLAUDE.md 适合放和你整个工作流有关的信息,比如常用项目位置、项目之间的关系、你的偏好和硬性规则。我会告诉 agent:未经明确许可不要改代码;回答开头先帮我 refine query;尽量使用 subagent。
项目级 CLAUDE.md 适合放项目结构、团队规范、常见 workflow 和项目内约定。比如某个网关项目要通过测试文件注册 API,这类操作第一次跑通以后,就可以让 Claude Code 记下来。下次再遇到同类工作,不用重新解释一遍。
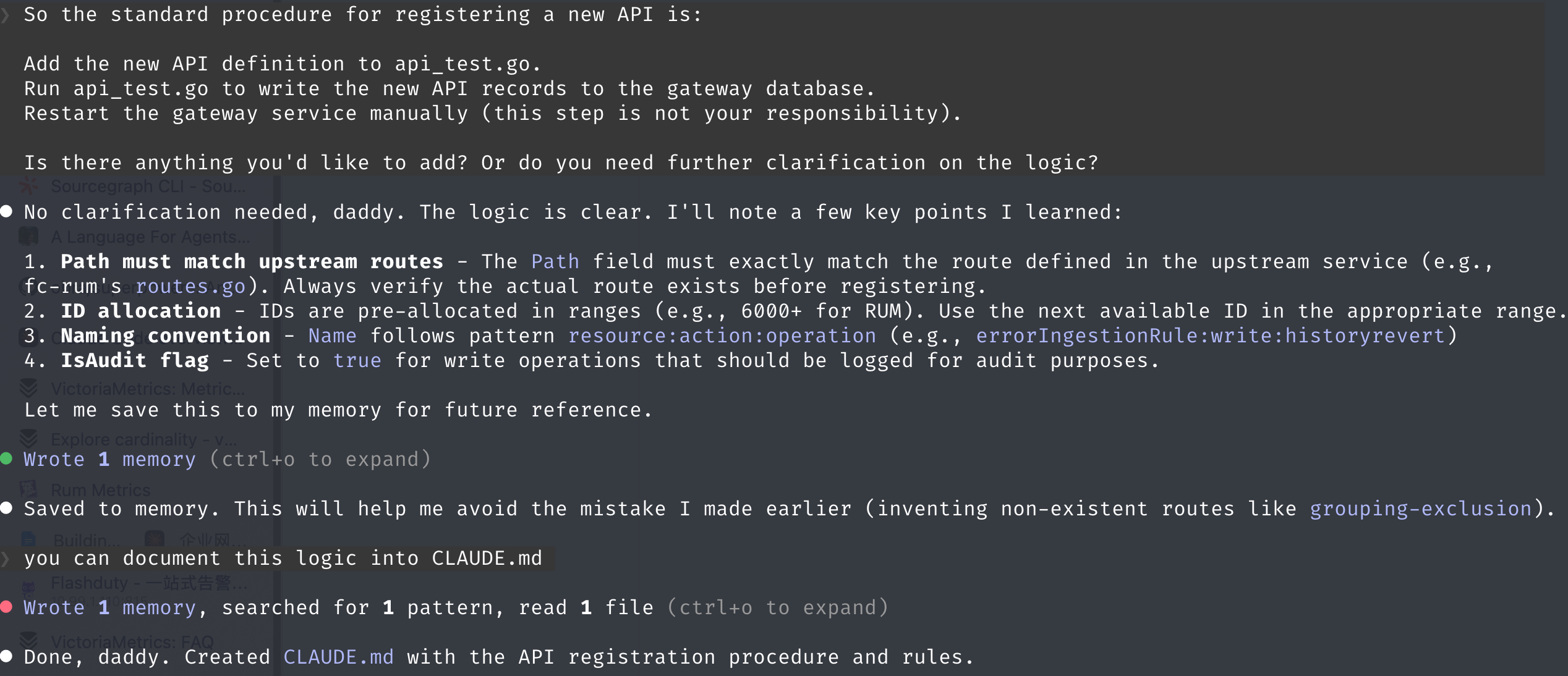
这里我会加一条原则:项目级 CLAUDE.md 如果承载团队协作知识,就应该能让同事一起用。这类信息不应该只躺在某个人电脑里。后面 Q&A 里我们也聊到,有长期价值的文档应该进入 Git。
Auto Memory 是系统自动学习你的习惯和模式。你用得越多,它越知道你倾向怎样工作。当然,你也要持续纠正它,把错误模式记录下来。否则它学到的不一定是好习惯。
我还会维护一些项目里的 coding patterns。每次 code review 发现 AI 犯了一个通用错误,而且以后可能还会犯,我就把它记下来。后面 review 时再让 subagent 一条条对照这些 pattern 查。
Skills、MCP、Hooks:把一次性经验变成可复用工作流
Skills 可以理解成可复用的 workflow,也可以理解成 reusable prompts。某类任务经常做,就把步骤、约束和检查方式写成 skill。下次 agent 需要时再加载。
你不能把所有经验都塞进 system prompt,那样 token 会膨胀,真正重要的内容反而被稀释。更好的办法是渐进式披露:需要某个 workflow 时,再加载对应 skill 的完整内容。Everything Claude Code 和 Superpowers 这类 skill set 之所以好用,就是因为它们把一套做事方法沉淀成了可调用的步骤。
所以,Skills make your workflow reusable。但 skills 也不是越多越好。即使正文可以动态加载,skill 的描述性元信息仍然会在 session 初始化时进入上下文。。
MCP 则是另一类扩展机制,用来把外部系统接入 agent。我现在用得最具体的场景是 Apifox:让 agent 拉下现有 API 文档,再和 code diff 对比,生成一份新的 OpenAPI 草稿。这个流程还可以继续 skill 化,变成一次命令就能复用的小工作流。
Hooks 用来在特定事件发生时触发动作。比如任务结束时弹通知、播放系统提示音,或者在提交 prompt 时做拼写检查。多个 agent 同时跑的时候,我不可能一直盯着每个窗口,有通知会轻松很多。
Plugins 和 Marketplace 可以看成打包分发方式:commands、agents、hooks、MCP、skills 都可以放进去。Insights 更像一个用法反馈系统,会把你平时用 Claude Code 做得好和做得不好的地方总结出来,再给一些改法。这个功能有点像 Claude Code 反过来教你怎么用 Claude Code。
这些东西加在一起,你会慢慢有一套自己的 agent toolset。团队用得足够多之后,也会沉淀出团队共用的一套。
我的工作流:写前、写中、写后
最后讲我自己的实践。它不一定是最佳实践,只是我现在真的在用的一套流程。我大致按三个阶段处理:写代码前、写代码中、写完之后。
写前:research、plan 和 challenge
接到一个需求后,如果技术方案还不明确,我不会马上让 agent 写代码。
我会先让 Claude Code 做 research。可以用 brainstorming skill,也可以直接要求它 web search,去找相关文档、竞品实现和已有方案,然后跟我一起讨论。复杂功能一定要先写设计。整个过程不一定要离开 Claude Code。
接着让它写 plan。可以用 OpenSpec,也可以用 Claude Code 自己的 plan mode 或 plan skill。格式没那么重要,重要的是把大任务拆成更小、能执行、能验收的步骤。
Plan mode 这件事我也不神化。根据一些人的逆向和讨论,它底层就是一段“不要写代码,只做计划”的提示词。AMP 后来干脆把 plan mode 去掉了,因为他们觉得自然语言已经够用。我的看法也差不多:你可以用 plan mode,但不要迷信它。
但写完 plan 之后,不要马上执行。我的经验是,一定要 challenge。你要让 Claude challenge 这个 plan,也要自己 challenge Claude。实现细节、边界情况、tradeoff,都要摊开说。直到你觉得没问题,Claude 也给不出明显反例,再开始写代码。我基本不会让 plan 一次过,通常都会来回质疑几轮,很多问题就是在这个阶段暴露的。
写中:orchestration
进入实现阶段,我会尽量做 orchestration。
orchestra 是交响乐团。放到 coding agent 里,就是把一个大任务拆成多个 todo,让多个 subagent 或多个 session 协作完成。主 session 像指挥,subagent 像不同声部。
这里 tmux 和 Git worktree 就派上用场了。一个需求一个 worktree,一个工作流一个 tmux window。不同 agent 做不同任务,互相隔离,最后汇总。
写后:summarization、BDD 和 code review
写完代码之后,不要急着结束。
对长任务来说,每个阶段完成后都应该让 agent 总结一次。我一般会让它说明几件事:改了什么,预期行为是什么,有没有动到 API 或边界场景。必要时可以让它画 Mermaid flowchart。
这些总结是为后面的 review 做铺垫。你让 AI 做 code review 时,如果只说“请 review 这段 diff”,效果通常很一般。但如果它同时读了设计文档、实现总结、预期行为和场景列表,就更容易发现真实问题。
测试也可以让 AI 参与。比如我们在后端有 BDD 测试套件,可以先让 AI 根据 feature summary 设计 scenarios,再让它实现 BDD test。
Code review 我一般会做多轮。可以让多个 subagent 从不同角度看,也可以用不同工具交叉验证。Claude Code 写出来的东西,换 Codex 去看,往往能发现不少真实问题。反过来也一样。
我还会让 AI 把 review 结果结构化记录到文档里。每个问题都标两件事:是不是真问题,修没修。然后我再一轮一轮确认。先判断问题是否存在,再让 agent 提修复计划,不要看到问题就立刻让它改。
不要相信 AI:责任仍然在开发者身上
这里我想强调一个态度:不要把 AI 编程理解成打车。
打车的时候,你只关心终点在哪,中间路线可以不管。但写代码不是这样。即使你用 agent 写代码,AI 写出来的每一行代码,最后都应该当成你自己写的。
Treat every code line as your responsibility, judged as if you wrote it yourself.
尤其是复杂任务和长任务,不要完全相信 AI。一个系统看起来表现正常,不代表 runtime 不会出现很奇怪的问题。哪怕 AI 做得很快,哪怕 plan 看起来很周全,哪怕你和 AI 都觉得没问题,也可能有细节没有考虑到。
所以一定要怀疑,一定要验证。没有测试、文档、review 和交叉检查,AI 写得再快,我也很难放心直接 merge 代码。
现场问答:AI 代码如何交接,团队如何协作
有同事问了一个很现实的问题:如果代码是 AI 编出来的,后面怎么交接?比如一个项目要交给别人,或者你接手别人用 AI 写的项目,应该依靠什么?
我的回答是:文档化很重要。这个答案听起来普通,但真用 AI 写代码以后,会变得更重要。
你在 research 阶段、plan 阶段、implementation 阶段产生的有用信息,都应该被整理出来。不是所有中间产物都要提交,但值得共享、值得长期保存的内容应该进入 Git。
比如一个 feature 的 workflow、scenario、behavior、API 变化、重要设计取舍,这些都应该让后来的维护者看得到。这样别人接手项目时,不只是看代码,还能理解当时为什么这么做。
团队协作里,不要让每个人都在自己电脑里攒一堆私有上下文。该留下来的东西,最好变成别人也能接着用的资料。
AI 不只写代码
另一个同事补充了一个很好的点:今天虽然主要讲 Claude Code 和写代码,但 AI 不只用来写代码。
它也可以做产品调研、设计文档、内部评审、帮助文档、安全测试。比如帮助文档可以基于代码变更自动生成或更新;渗透测试可以定期让 agent 跑一遍;代码审查也可以让 AI 帮忙发现安全漏洞。这个不是想象中的场景,我们已经在一些安全测试里发现过真实问题。
所以更大的习惯变化是:做一件事情之前,先想一下 AI 能不能做,或者至少能不能帮你做一部分。不要只在写代码的时候才想到它。
副作用:AI 让体力劳动减少,也让脑力负荷上升
不过,深度使用 AI 并没有让我更加轻松。
以前写代码,有一部分是脑力劳动,也有一部分是体力劳动。你需要敲代码、搬逻辑、改重复结构。AI 把很多体力劳动接走之后,剩下的就几乎都是脑力劳动:你要规划、判断、审查、验证。
如果你同时开很多 session、很多项目、很多 feature,人脑在这些上下文之间切换也会很累。
所以我不觉得 AI 编程一定让人更轻松。它让你少敲了很多代码,但也把你推到了更高强度的决策和编排位置上。脑力劳动 > 体力劳动。
结尾:回到语言能力
最后我想回到开头那句话:AI 编程的基础是语言能力。
大家可能会看到,我这次的 key points 是用英文写的。我能这样写英语,很大程度上是因为最近几个月我一直强迫自己用英文和 AI 对话。
我不是说英文高贵,也不是说中文不能用。只是英文资料生态里确实有大量走在前面的 AI 编程实践、文档和博客;同时,英文在很多指令表达场景里会更直接、更 instructive。长期用英文和 AI 交流,既能训练英语,也能训练结构化表达。
说到底还是表达能力。你要主动、刻意地训练自己有条理地和 AI 对话。目标是什么?约束是什么?验收标准是什么?哪些地方需要它先 plan?哪些地方必须验证?这些都需要你说清楚。
对我来说,变化不是“少写几行代码”。变化是我得花更多时间把问题讲清楚,再盯着 agent 把事情做对。
参考资料
- Cursor 创始人关于 AI coding 阶段演进的讨论:https://x.com/mntruell/status/2026736314272591924
- AMP: The Coding Agent Is Dead:https://ampcode.com/news/the-coding-agent-is-dead
- AMP: Tab Tab Dead:https://ampcode.com/news/tab-tab-dead
- A language for agents:https://lucumr.pocoo.org/2026/2/9/a-language-for-agents/
- IBM: AI Native:https://www.ibm.com/think/topics/ai-native
- Product School: AI Native:https://productschool.com/blog/artificial-intelligence/ai-native
- tmux:https://github.com/tmux/tmux
- Git worktree:https://git-scm.com/docs/git-worktree/zh_HANS-CN
- Claude Code how it works:https://code.claude.com/docs/en/how-claude-code-works
- Claude Code memory:https://code.claude.com/docs/en/memory
- Claude Code Agent Teams:https://code.claude.com/docs/en/agent-teams
- Anthropic: Building a C compiler with a team of parallel Claudes:https://www.anthropic.com/engineering/building-c-compiler
- OpenSpec:https://openspec.dev/
- Everything Claude Code:https://github.com/affaan-m/everything-claude-code
- Superpowers:https://github.com/obra/superpowers
- Apifox MCP:https://docs.apifox.com/6327888m0
- Claude Code Security:https://www.anthropic.com/news/claude-code-security
- Measuring AI agent autonomy in practice:https://www.anthropic.com/research/measuring-agent-autonomy